
solved.ac 크롤링
크롤링
첫 포스트에서 solved.ac의 각 문제 티어 별 레이팅을 알아보려 했다.
사실 크롤링을 배운지 1주일 밖에 되지 않아서 기본적인 부분에서도 상당히 헤맸다.
Beautiful Soup
처음엔 Beautiful Soup 패키지로 크롤링을 시도했다.
import requests
from bs4 import BeautifulSoup
url = 'https://solved.ac/profile/luciaholic'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
solved.ac 프로필을 요청받아 BeautifulSoup에 넘겨줬다.
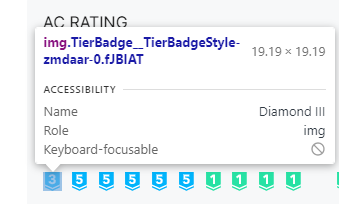
css_selector = '#__next > div.ProfileLayout__Background-sc-1nlq07q-0.bVKlxK > div.contents.no_top_margin > div:nth-child(1) > div.ProfileRatingCard__ProblemsContainer-sc-989yd6-3.kBcVFT > div:nth-child(1) > div:nth-child(1) > a > img'
이후 크롬 개발자 도구를 이용해 문제의 티어를 나타내는 이미지의 HTML 코드 부분의 CSS Selector를 복사해왔다.
soup.select(css_selector)
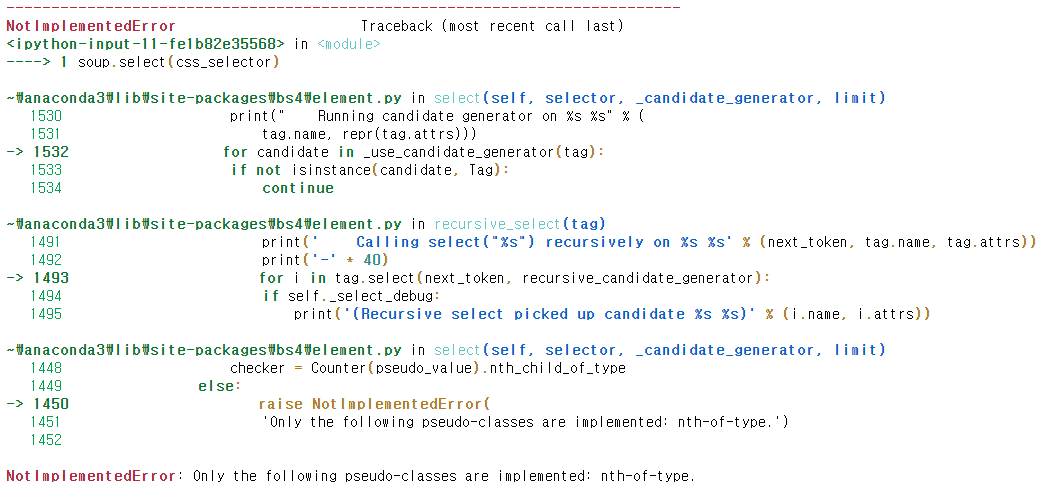
CSS Selector를 이용해 티어 이미지의 HTML 코드 부분을 불러오려 했으나 NotImplementedError가 발생했다.
구글링해보니 Beautiful Soup가 CSS Selector의 child 선택자 ‘nth-child()’를 지원하지 않기 때문에, ‘nth-of-type()’으로 바꿔줘야 한단다.
soup.select(css_selector.replace('nth-child', 'nth-of-type'))
# Out : []
그래서 변경한 Selector로 select 해봤는데, 빈 리스트가 반환됐다.
뭐가 잘못된지 몰라서 개발자 도구 상의 HTML 코드와 soup.text를 한참을 비교해봤다.
관찰 결과, 개발자 도구의 HTMl 코드엔 존재하지만 soup엔 담기지 않은 부분이 존재했다.
구글링해보니 Beautiful Soup은 동적 페이지에 적합하지 않다고 한다.
그래서 Selenium을 이용해보았다.
Selenium
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
path = '~~~/chromedriver.exe'
driver = webdriver.Chrome(path)
driver.get('https://solved.ac/profile/luciaholic')
search = driver.find_element_by_css_selector('#__next > div.ProfileLayout__Background-sc-1nlq07q-0.bVKlxK > div.contents.no_top_margin > div:nth-child(1) > div.ProfileRatingCard__ProblemsContainer-sc-989yd6-3.kBcVFT > div:nth-child(1) > div:nth-child(1) > a > img')
동일한 CSS Selector로 크롤링을 진행했다.

필자는 HTML을 전혀 모르기에, 구글링 해본 결과 맨 앞의 img는 해당 객체가 이미지 요소라는 것, src는 이미지 파일의 경로, 그리고 alt는 이미지의 텍스트 설명을 의미한다고 이해했다.
내가 필요했던 것은 티어 정보였으므로 alt 값만 불러오면 된다.
search.get_attribute('alt')
# Out : 'Diamond III'
이 과정을 반복하기 위해 HTML 코드를 조금 더 살펴보았다.
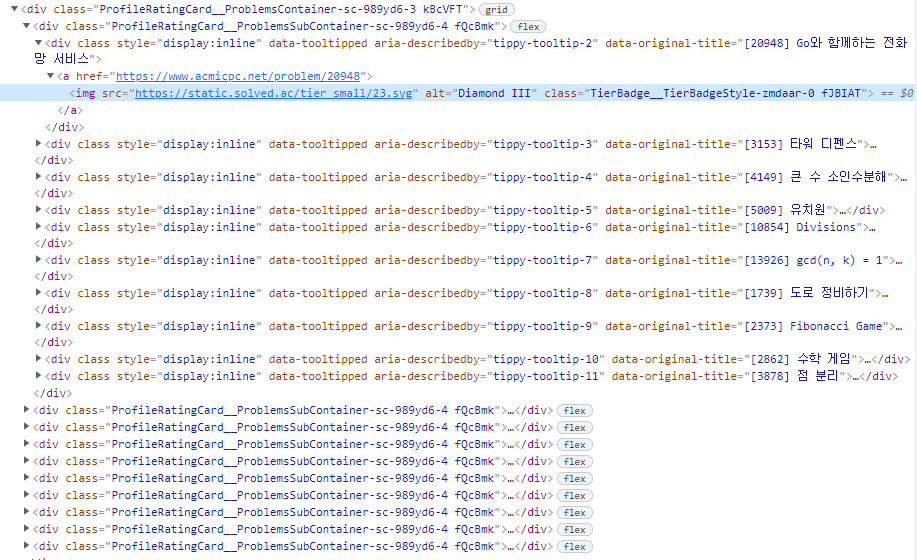
<div class="ProfileRatingCard__ProblemsContainer-sc-989yd6-3 kBcVFT">
상위 100문제의 정보들은 위 element에 담겨있었고,
<div class="ProfileRatingCard__ProblemsSubContainer-sc-989yd6-4 fQcBmk">
10문제씩 위 element에 나눠 담겨있었다.
#__next > div.ProfileLayout__Background-sc-1nlq07q-0.bVKlxK > div.contents.no_top_margin > div:nth-child(1) > div.ProfileRatingCard__ProblemsContainer-sc-989yd6-3.kBcVFT > div:nth-child(1) > div:nth-child(1) > a > img
CSS Selector를 보면, ~ ProblemsContainer ~ > div:nth-child(1) (1번째 자식) > div:nth-child(1) (1번째 자식) > a (a 요소) > img (img 요소)로 HTML 코드와 일맥상통함을 알 수 있다.
containers = driver.find_element_by_css_selector('#__next > div.ProfileLayout__Background-sc-1nlq07q-0.bVKlxK > div.contents.no_top_margin > div:nth-child(1) > div.ProfileRatingCard__ProblemsContainer-sc-989yd6-3.kBcVFT')
tier = []
for i in range(1, 11):
sub_container = containers.find_element_by_css_selector(f'div:nth-child({i})')
for j in range(1, 11):
problem = sub_container.find_element_by_css_selector(f'div:nth-child({j}) > a > img')
tier.append(problem.get_attribute('alt'))
ProblemsSubContainer가 10개고 각 SubContainer에 10개의 이미지 파일이 있으니까 이런 식으로 코드를 짰다.

그런데 i = 2, j = 1일 때 NoSuchElementException Error가 발생했다.
2번째 sub_container의 1번째 child > a > img를 참조할 수 없던 것이었다.
sub_container = containers.find_element_by_css_selector('div:nth-child(1)')
problem = sub_container.find_element_by_css_selector('div:nth-child(1) > a > img')
print(problem.get_attribute('alt'))
위 코드에서 괄호 안 숫자를 바꿔가며 테스트했더니, i가 1이거나 i == j일 때만 오류가 발생하지 않았다.
i가 1일 땐 정상적인 값이 나왔는데, i == j일 땐 최상위 i번째 결과가 나왔다. (1번째 SubContainer의 j번째 값)
이 과정에서 Selenium이 엄청나게 불편하다고 느꼈다.
왜냐하면 Beautiful Soup의 find/find_all 메서드는 타겟 element 전부를 리턴하는 반면, Selenium은 get_attriubute, get_property 메서드만 존재할 뿐 element 전체를 확인할 방법이 없었다.
sub_container = containers.find_element_by_css_selector('div:nth-child(1)')
sub_container.get_attribute('class')
# Out : 'ProfileRatingCard__ProblemsSubContainer-sc-989yd6-4 fQcBmk'
sub_container = containers.find_element_by_css_selector('div:nth-child(2)')
sub_container.get_attribute('data-original-title')
# Out : '[3153] 타워 디펜스'
그러던 도중 이상한 점을 발견했다.
해당 SubContainer의 첫 번째 element의 data-original-title은 ‘[20948] Go와 함께하는 전화망 서비스’이다.
그런데 nth-child()의 값이 1 증가했는데 이 문제를 뛰어넘고 해당 SubContainer의 두 번째 element가 반환된 것이다.
nth-child() 선택자가 생각보다 단순한 게 아닐 거란 생각이 들어 구글링을 해보았지만 발생한 문제에 대한 정확한 원인을 파악할 수 없었다.
for i in range(1, 11):
for j in range(1, 11):
problem = problem_containers.find_element_by_css_selector(f'div:nth-child({i}) > div:nth-child({j}) > a > img')
print(problem.get_attribute('alt'))
# Out : Diamond III ... Platinum V
CSS Selector에 대해선 나중에 깊게 다뤄보기로 하고, 일단 위와 같은 방식으로 크롤링 할 수 있었다.
from collections import defaultdict
tier = defaultdict(int)
for i in range(1, 11):
for j in range(1, 11):
problem = problem_containers.find_element_by_css_selector(f'div:nth-child({i}) > div:nth-child({j}) > a > img')
tier[problem.get_attribute('alt')] += 1
print(tier)
# Out : defaultdict(int,
# {'Diamond III': 1,
# 'Diamond V': 5,
# 'Platinum I': 9,
# 'Platinum II': 8,
# 'Platinum III': 22,
# 'Platinum IV': 30,
# 'Platinum V': 25})
tier라는 defaultdict에 카운팅을 해주었고, 계산 결과 P5 = 16, P4 = 17, …, D3 = 23 레이팅임을 알 수 있었다.
그냥 단순하게 B5 = 1부터 시작하는 것이었다.

Leave a comment